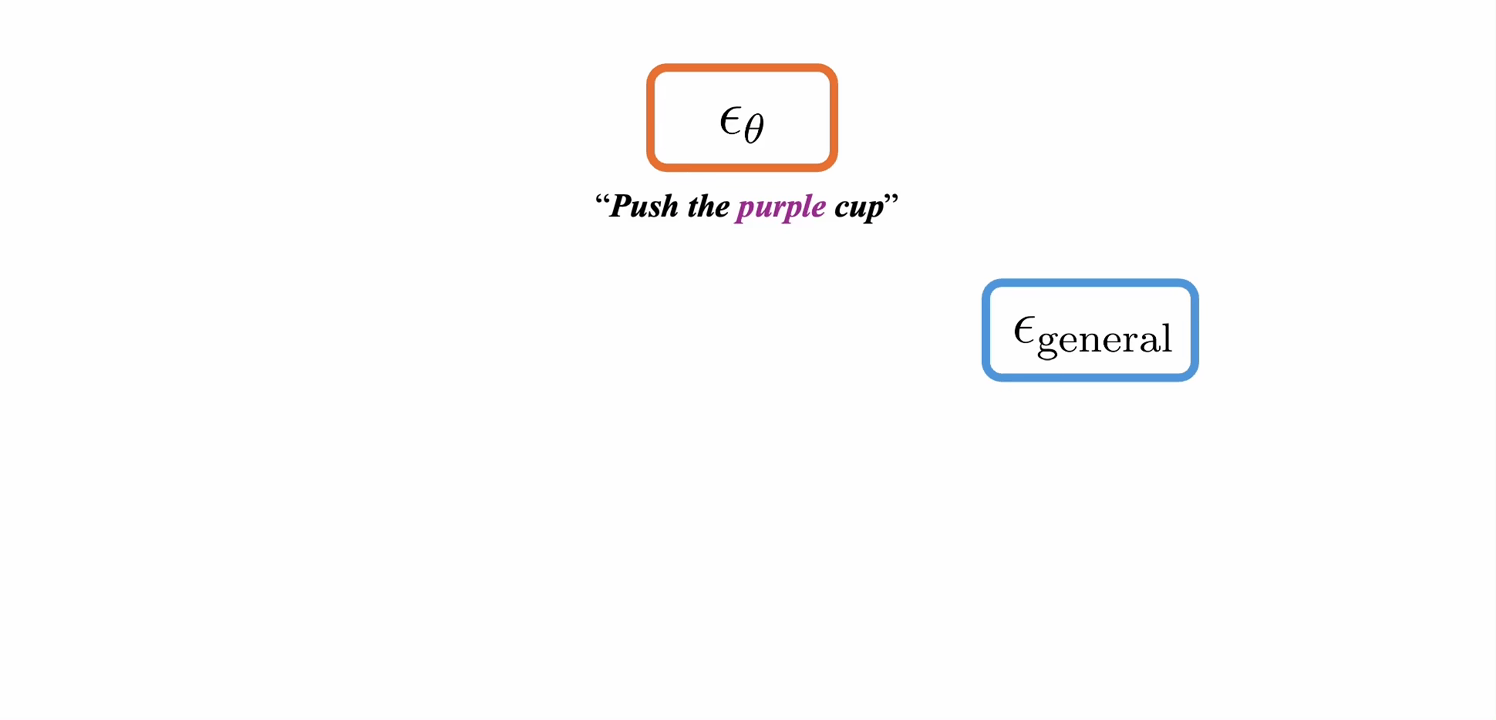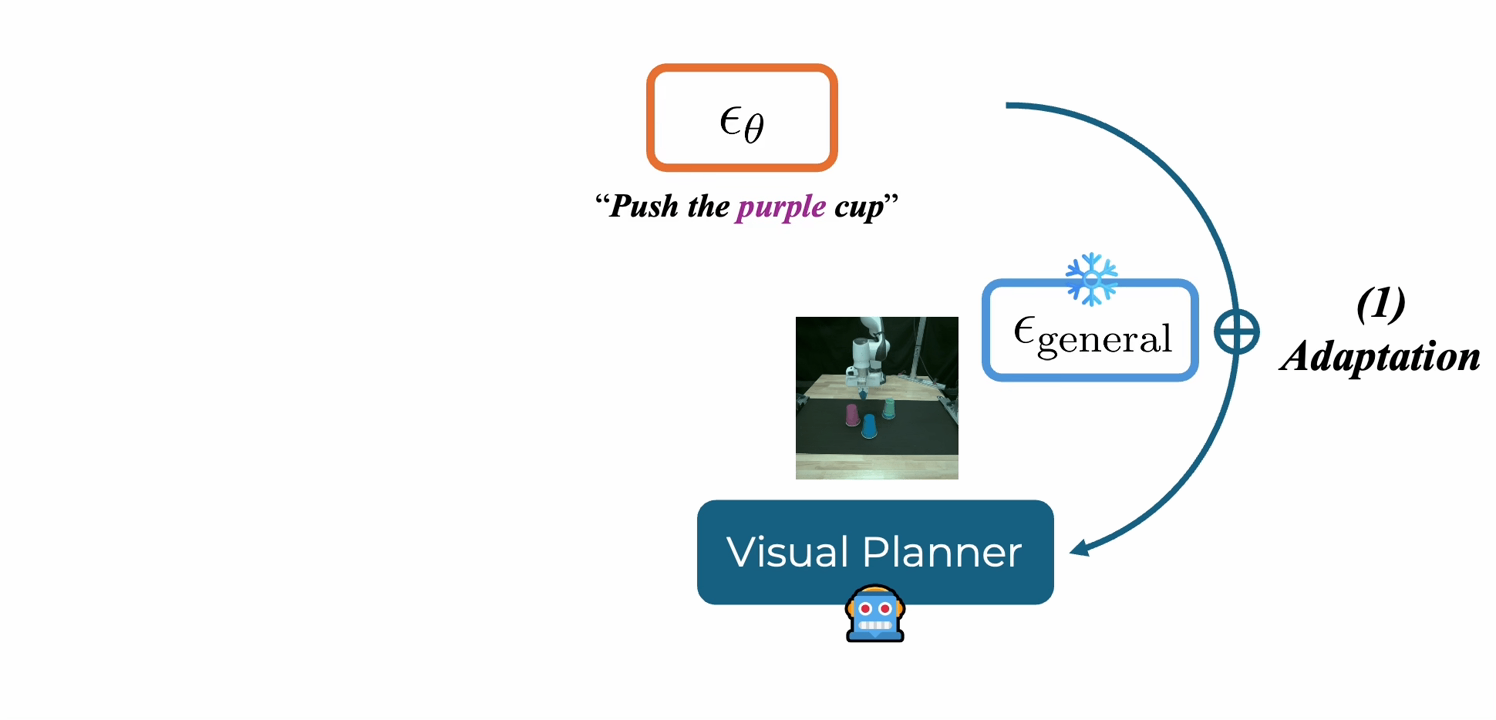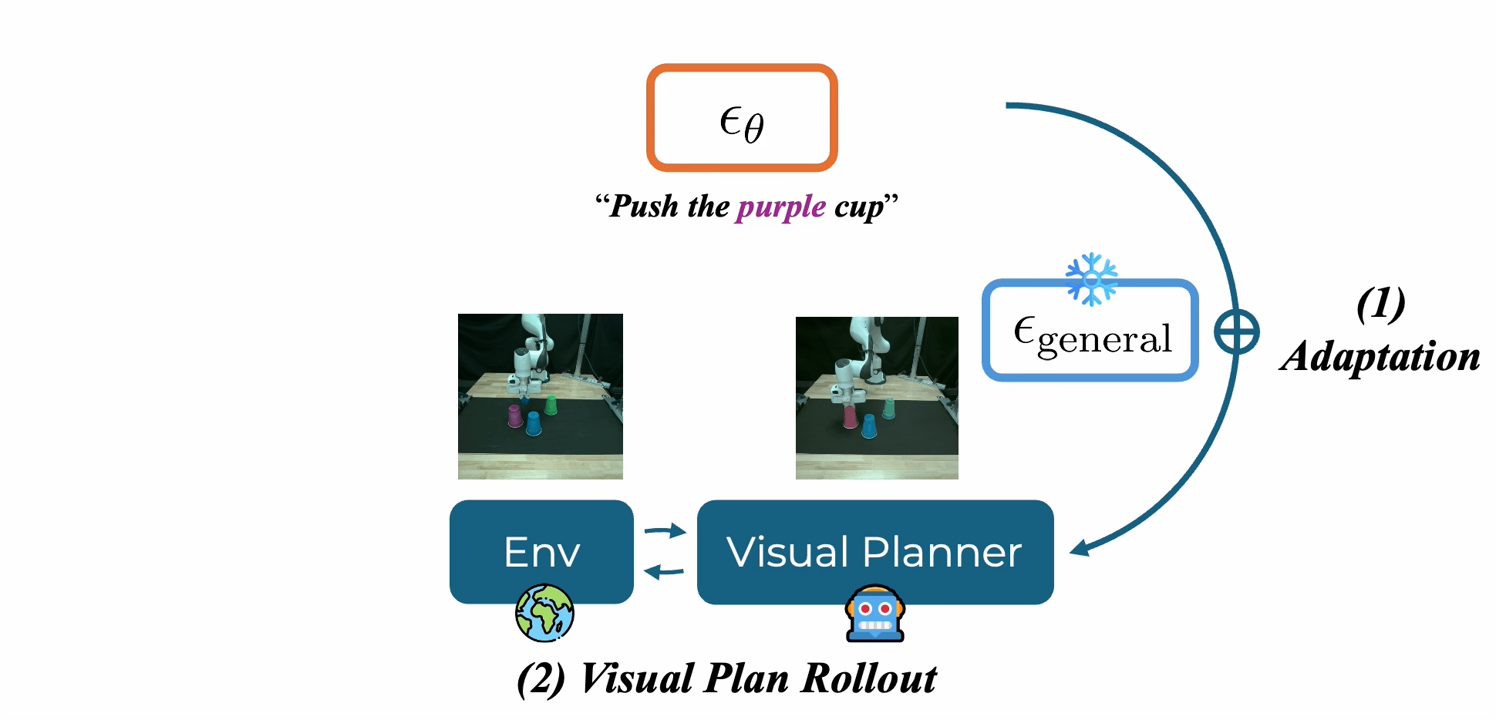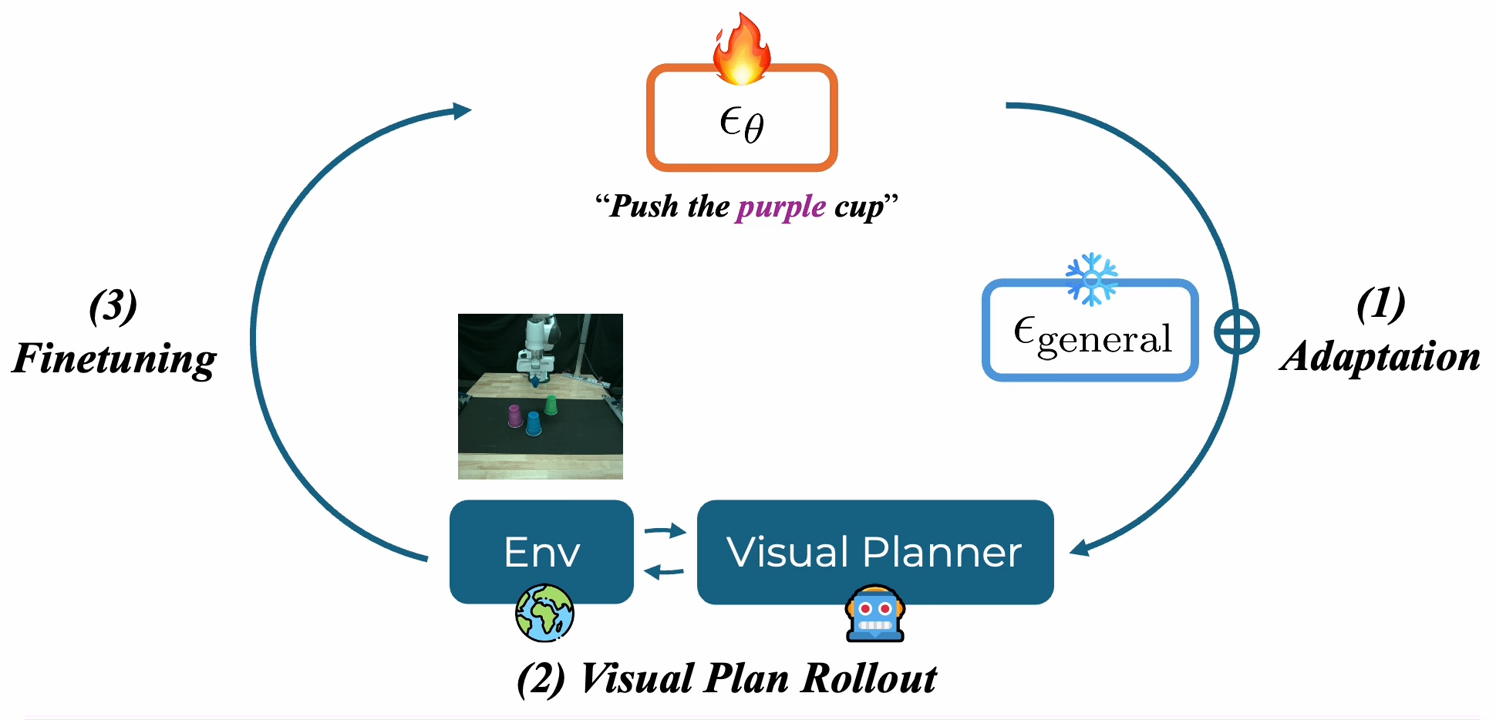
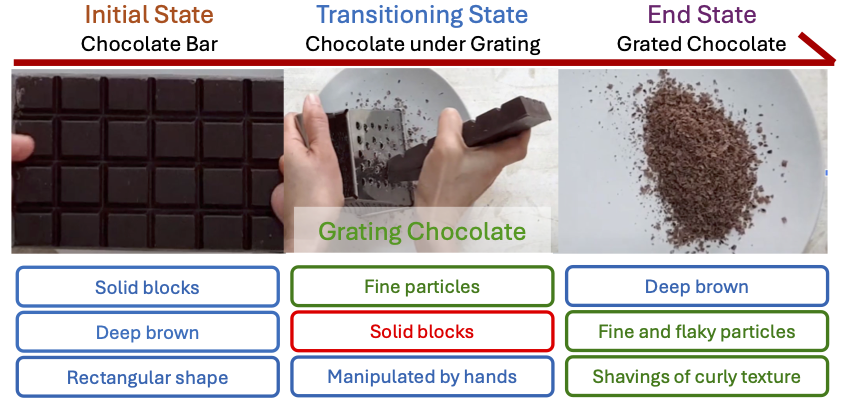
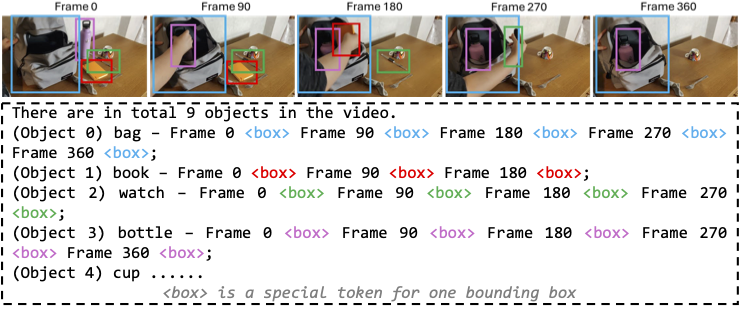
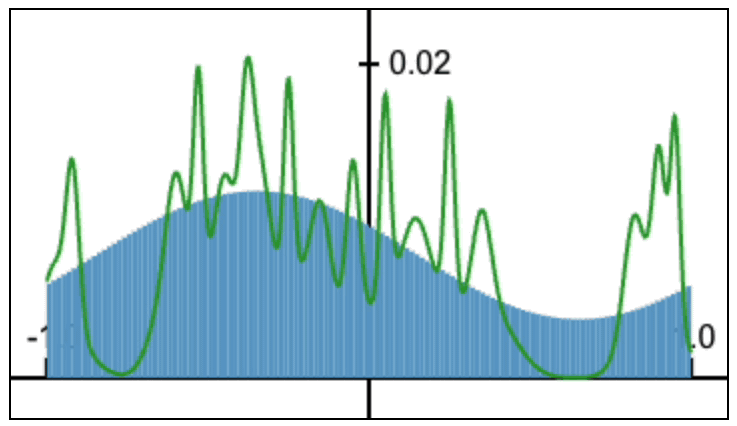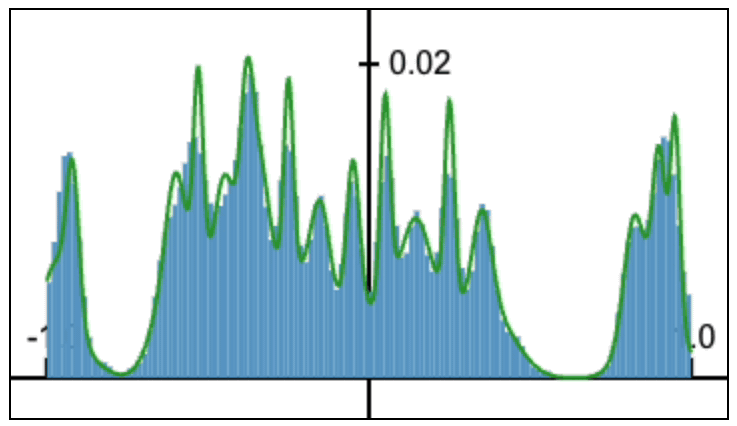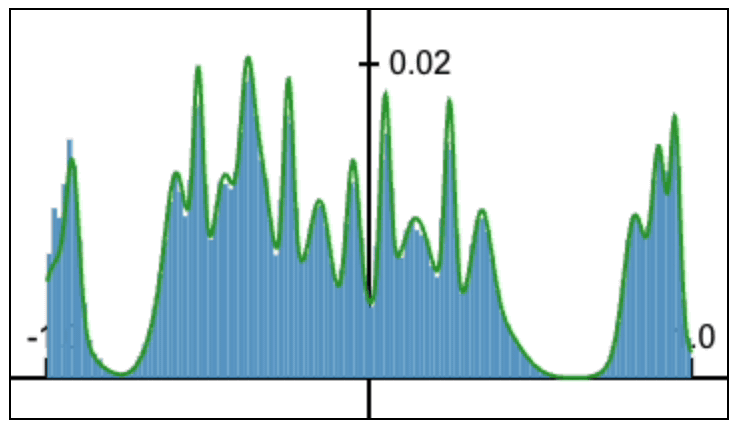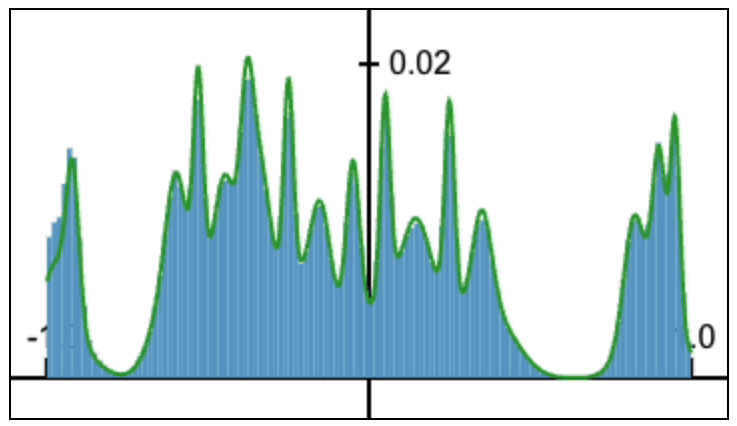
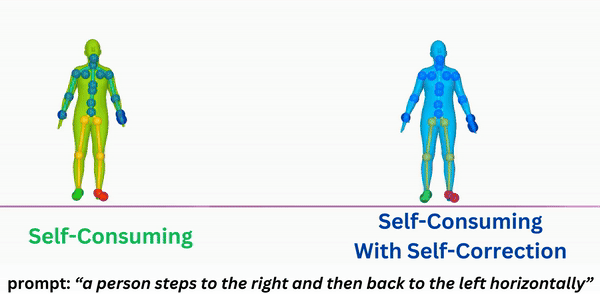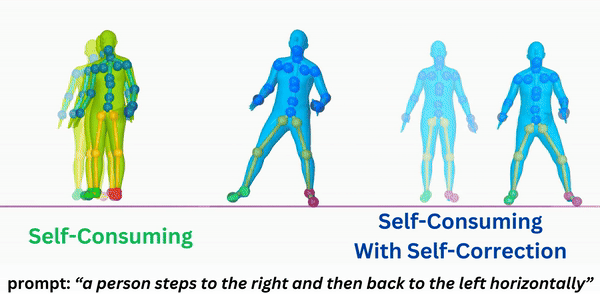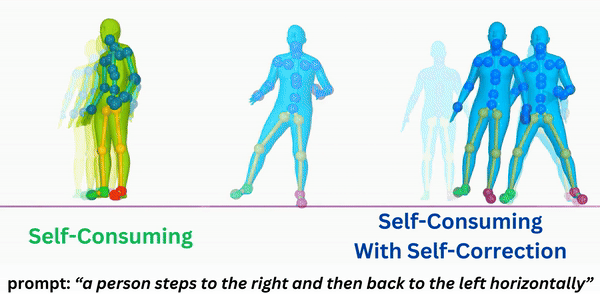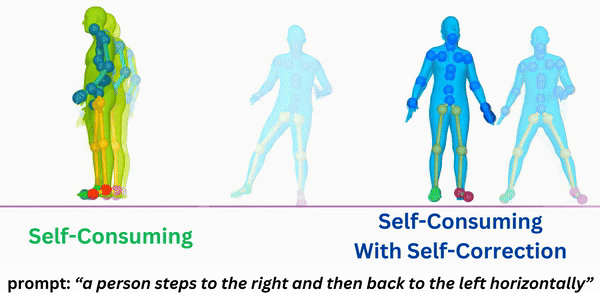
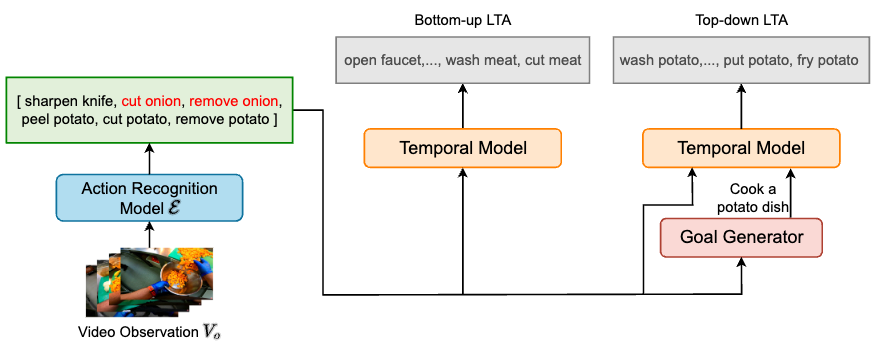
About Me
I am an assistant professor of computer science at Brown University, where I direct the PALM🌴 research lab, studying computer vision, machine learning, and artificial intelligence. I work part-time as a staff research scientist at Google DeepMind.
Our research focuses on multimodal concept learning and reasoning, as well as controllable, principled, and scalable image and video generation, and their applications in robotic planning and control. A long-standing research tradition of the lab is video understanding.
Previously, I received my Ph.D. from the University of Southern California in 2016, advised by Prof. Ram Nevatia. I completed my bachelor degree in Computer Science at Tsinghua University in 2011.
I have received Brown University's Richard B. Salomon Faculty Research Award and Samsung's Global Research Outreach Award for multimodal concept learning from videos. My research on behavior prediction appeared in the CVPR 2019 best paper finalist. Our lab's research has been supported by Adobe, Honda, Meta, NASA, and Samsung. Our lab is a member of the NSF AI Research Institute on Interaction for AI Assistants.
My office hours are 3:30 to 5:00 pm ET on Tuesdays at CIT 379.
Teaching
- CSCI 2470, Deep Learning, Fall.
- CSCI 2952-N, Advanced Topics in Deep Learning, Spring.
- Short course on Multimodal Transformers, ICASSP 2022 and AAAI 2023.
- CSCI 2950-K, Special Topics in Computational Linguistics (co-taught with Eugene Charniak), Fall 2020.
Group
PhD students
- Apoorv Khandelwal (Presidential Fellow, co-advised with Ellie Pavlick)
- Calvin Luo (Research Mobility Fellow, visiting Stanford via IvyPlus)
- Nate Gillman (Department of Mathematics)
- Shijie Wang
- Tian Yun (Co-advised with Ellie Pavlick)
- Yuan Zang
- Zilai Zeng
- Zitian Tang
Alumni
- Kaleb Newman (class of 2025 at Brown, CRA Honorable Mention, now PhD student at Princeton CS)
- Michael Freeman (class of 2020 at Brown, now PhD student at Cornell CS)
- Rohan Krishnan (class of 2025 at Brown, now engineer at Klaviyo)
- Chia-Hong Hsu (master of 2025 at Brown, now PhD student at UBC)
- Kevin Zhao (master of 2024 at Brown, now researcher at TikTok)
- Zilai Zeng (master of 2024 at Brown, now PhD student at Brown CS)
- Yunhao Luo (master of 2024 at Brown, now PhD student at UMich CS)
- Mandy He (class of 2024 at Brown, now software engineer at Duolingo)
- Minh Quan Do (master of 2024 at Brown, now co-founder at Tan Kim Nhat Trading)
- David Heffren (class of 2024 at Brown, now PhD student at JHU Applied Math)
- John Ryan Byers (class of 2024 at Brown, now master student at Cornell Tech)
- Ce Zhang (master of 2023 at Brown, now PhD student at UNC CS)
- Changcheng Fu (master of 2023 at Brown, now PhD student at USC CS)
- Kunal Handa (class of 2023 at Brown, now member of technical staff at Anthropic)
- Jessica Li (class of 2023 at Brown, now software engineer at Headway)
- Tian Yun (master of 2022 at Brown, now PhD student at Brown CS)
- Usha Bhalla (class of 2022 at Brown, now PhD student at Harvard CS)
- Emily Byun (class of 2021 at Brown, now PhD student at CMU MLD)
Mentorship
Services
- Workshop Chair, CVPR 2025.
- Action Editor, TMLR.
- Area Chair, ICLR 2025 and 2026.
- Area Chair, CVPR 2020 to 2026.
- Area Chair, ICCV 2023 and 2025.
- Area Chair, ECCV 2022 and 2024.
- Area Chair, NeurIPS 2023 to 2025.
- Area Chair, ACL 2023.
- Senior PC, AAAI 2021 and 2022.
- Area Chair, WACV 2017 and 2018.