About Me
I am the Eliot Horowitz Assistant Professor of Computer Science at Brown University, where I direct the PALM🌴 research lab on computer vision, machine learning, and AI. I am also a part-time staff research scientist at Google DeepMind. I received my PhD from the University of Southern California in 2016 and my bachelor's degree in Computer Science at Tsinghua University in 2011. (Short bio)
Chen Sun is the Eliot Horowitz assistant professor of computer science at Brown University and a staff research scientist (part-time) at Google DeepMind, studying computer vision and machine learning. His current research focuses on learning temporal dynamics from unlabeled videos and applying these video-centric world models in robotics. Chen has received an NSF CAREER Award, a Richard B. Salomon Faculty Research Award, University Research Seed Award, and a Samsung Global Research Outreach Award. His work on behavior prediction in videos was a CVPR 2019 best paper finalist. Previously, Chen received his PhD from the University of Southern California in 2016 and bachelor's degree from Tsinghua University in 2011.
At PALM🌴, we focus on learning generalizable temporal dynamics from unlabeled videos, whether as multimodal concepts, human behaviors, or raw pixels. We are also exploring applications of these video-centric world models in robotics.
I have received an NSF CAREER Award, a Richard B. Salomon Faculty Research Award, a DOR Seed Award, and a Samsung Global Research Outreach Award. My work on behavior prediction was a CVPR 2019 best paper finalist. Our research has been supported by Adobe, Honda, Meta, NASA, NSF, NVIDIA, and Samsung over the years. We are a member of the NSF AI Research Institute on Interaction for AI Assistants (ARIA).
Research Highlight
My talk at the ICERM workshop on Agentic Scientific Computing and SciML (May 2026) highlights our recent research:
Teaching
Group
PhD students
PhD alumni
- Calvin Luo (PhD '26, Computer Science)
- Thesis: Generalizable Decision-Making via Large-Scale Visual Generative Models
- Research Mobility Fellowship, Joukowsky Outstanding Dissertation Prize Finalist
- Nate Gillman (PhD '26, Mathematics & Computer Science)
- Thesis: Controlling Deep Generative Models via Physical and Mathematical Priors
- Next position: Research Scientist at Google Research
- Shijie Wang (PhD '26, Computer Science)
- Thesis: From Text to Pixels: Multimodal Video Understanding with Language Pre-training
- Next position: Research Scientist at NVIDIA Cosmos Lab
- Tian Yun (PhD '26, co-advised with Ellie Pavlick)
- Thesis: Internal Representations in Vision-Language Models
- Next position: Research Scientist at Meta MSL
Undergraduate and MS alumni
- Adam Lalani (Brown '26, CS Senior Prize)
- Bozheng Li (Brown MS '26)
- Kaleb Newman (Brown '25, CRA Honorable Mention — PhD at Princeton CS)
- Michael Freeman (Brown '20 MS '24 — PhD at Cornell CS)
- Rohan Krishnan (Brown '25 — engineer at Klaviyo)
- Yuan Zang (Brown MS '25 - engineer at ByteDance)
- Chia-Hong Hsu (Brown MS '25 — PhD at UBC)
- Kevin Zhao (Brown MS '24 — researcher at ByteDance Seed)
- Zilai Zeng (Brown MS '24 — PhD at Brown CS)
- Yunhao Luo (Brown MS '24 — PhD at UMich CS)
- Mandy He (Brown '24, CS Senior Prize — engineer at Duolingo)
- Minh Quan Do (Brown MS '24 — co-founder at Tan Kim Nhat Trading)
- David Heffren (Brown '24, CS Senior Prize — PhD at JHU Applied Math)
- John Ryan Byers (Brown '24 — master's at Cornell Tech)
- Ce Zhang (Brown MS '23 — PhD at UNC CS)
- Changcheng Fu (Brown MS '23 — PhD at USC CS)
- Kunal Handa (Brown '23 — member of technical staff at Anthropic)
- Jessica Li (Brown '23, CS Senior Prize — engineer at Headway)
- Usha Bhalla (Brown '22 — PhD at Harvard CS)
- Emily Byun (Brown '21 — PhD at CMU MLD)
Mentorship
Services
- Workshop Chair, CVPR 2025.
- Action Editor, TMLR.
- Area Chair, ICLR 2025 and 2026.
- Area Chair, CVPR 2020 to 2026.
- Area Chair, ICCV 2023 and 2025.
- Area Chair, ECCV 2022 to 2026.
- Area Chair, NeurIPS 2023 to 2025.
- Area Chair, ACL 2023 and 2025.
- Senior PC, AAAI 2021 and 2022.
- Area Chair, WACV 2017 and 2018.
Selected Projects

|
Goal Force: Teaching Video Models To Accomplish Physics-Conditioned Goals
Nate Gillman, Yinghua Zhou, Zitian Tang, Evan Luo, Arjan Chakravarthy,
Daksh Aggarwal, Michael Freeman, Charles Herrmann, and Chen Sun
CVPR 2026
arXiv / Project / Code
|

|
DF-ExpEnse: Diffusion Filtered Exploration for Sample Efficient Finetuning
Calvin Luo, Chen Sun, and Shuran Song
ICML 2026
arXiv / Project / Code
|
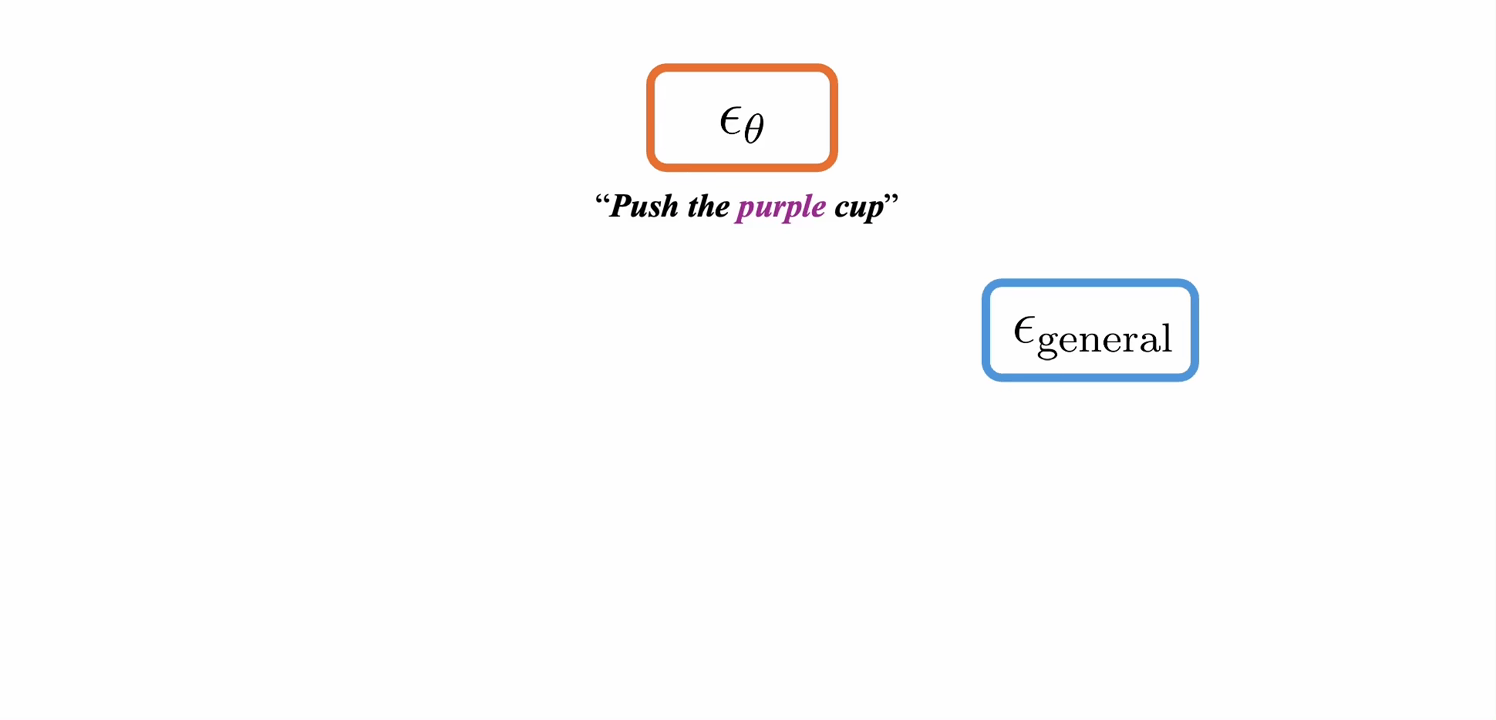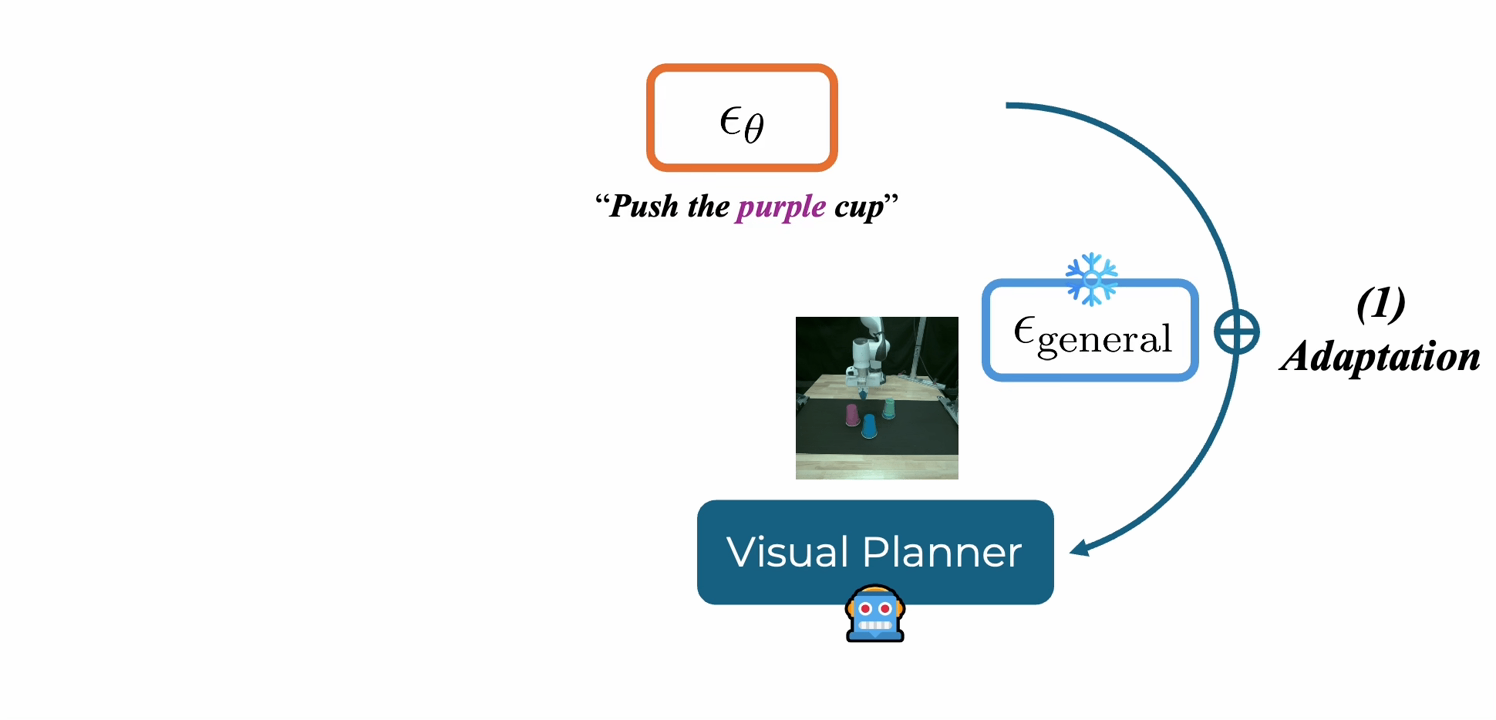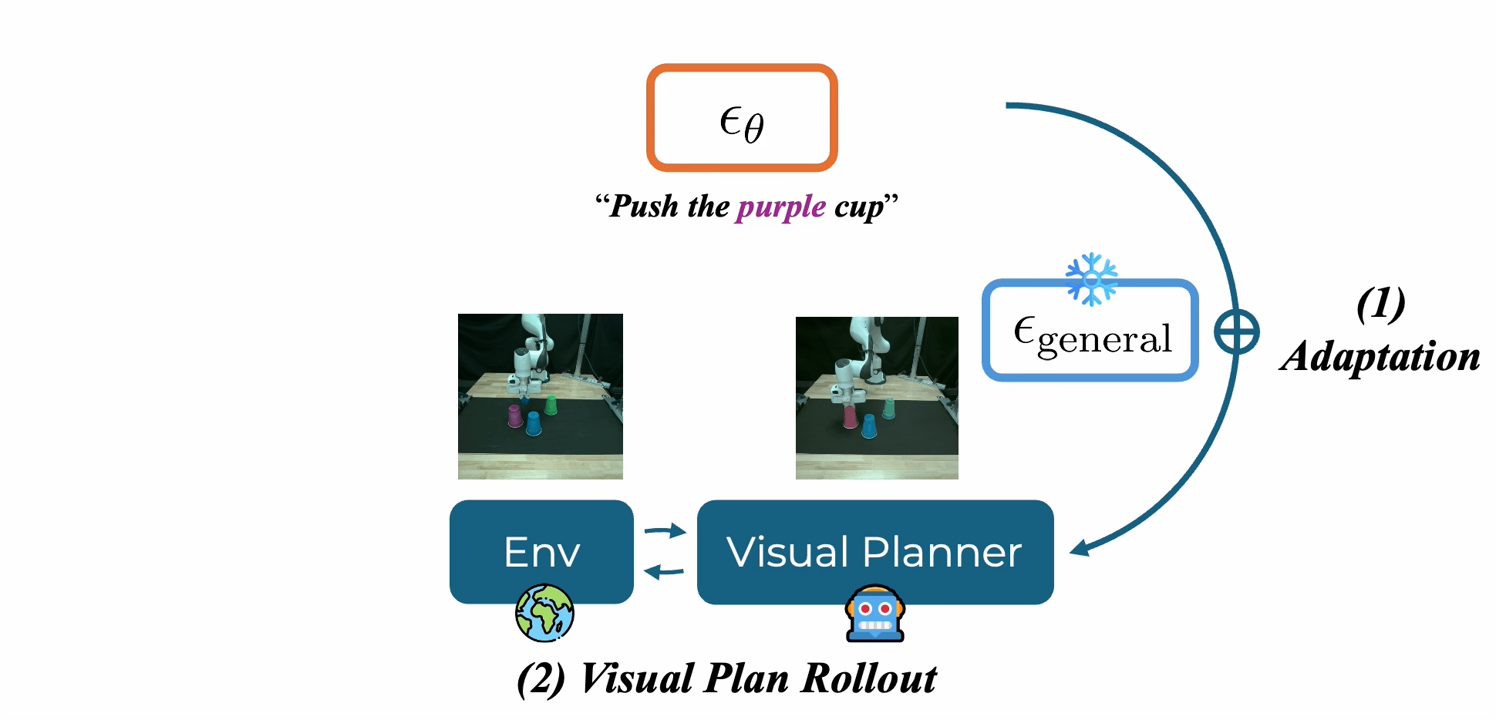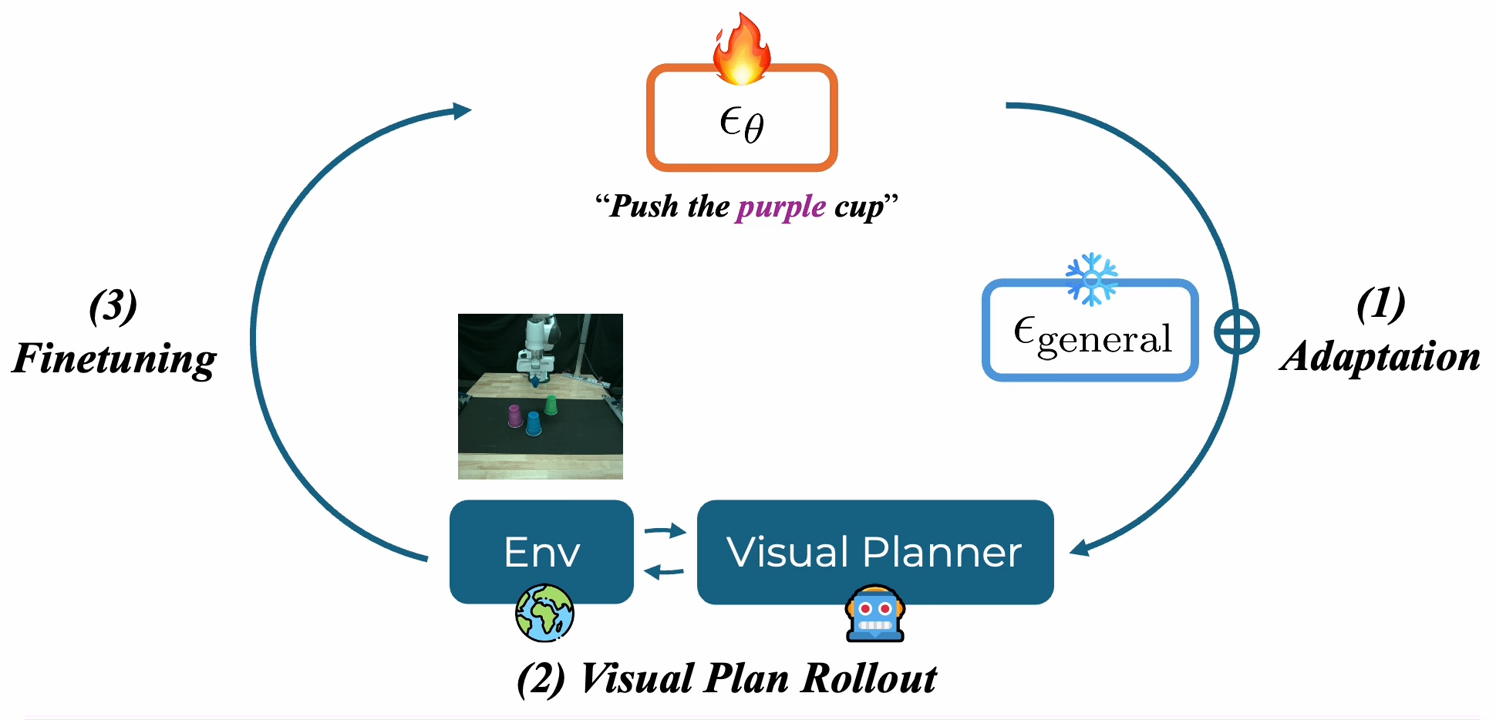
|
Self-Improving Loops for Visual Robotic Planning
Calvin Luo*, Zilai Zeng*, Mingxi Jia, Yilun Du, and Chen Sun
ICLR 2026
arXiv / Project / Code
|

|
Spacewalk-18: A Benchmark for Multimodal and Long-form Procedural Video Understanding in Novel Domains
Zitian Tang*, Rohan Myer Krishnan*, Zhiqiu Yu, and Chen Sun
WACV 2026 (Oral, Award Finalist)
arXiv / Project / Dataset
|

|
Force Prompting: Video Generation Models Can Learn and Generalize Physics-based Control Signals
Nate Gillman, Charles Herrmann*, Michael Freeman, Daksh Aggarwal, Evan Luo, Deqing Sun, and Chen Sun*
NeurIPS 2025
arXiv / Project / Code
|

|
How Can Objects Help Video-Language Understanding?
Zitian Tang, Shijie Wang, Junho Cho, Jaewook Yoo, and Chen Sun
ICCV 2025
arXiv / Project / Code
|
|
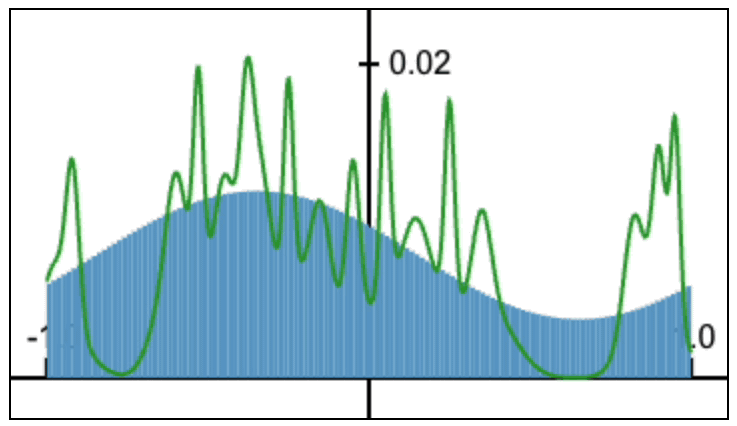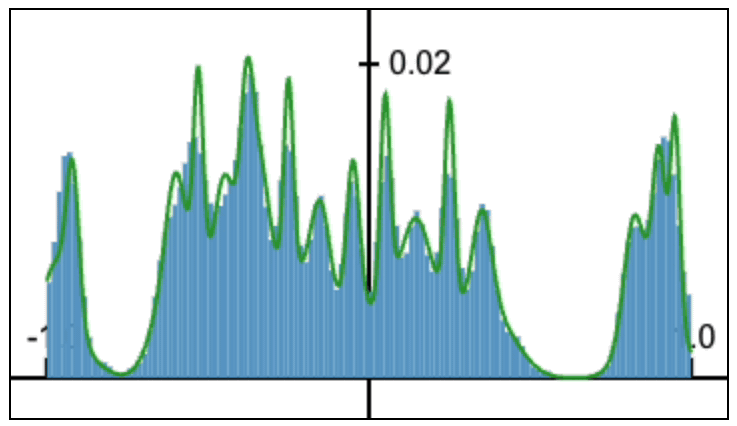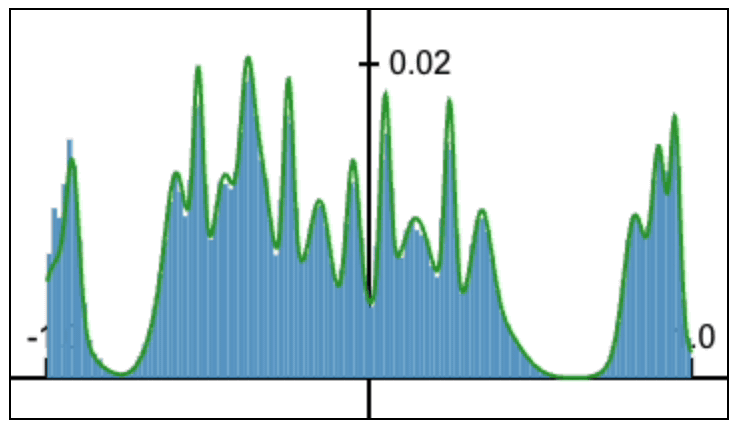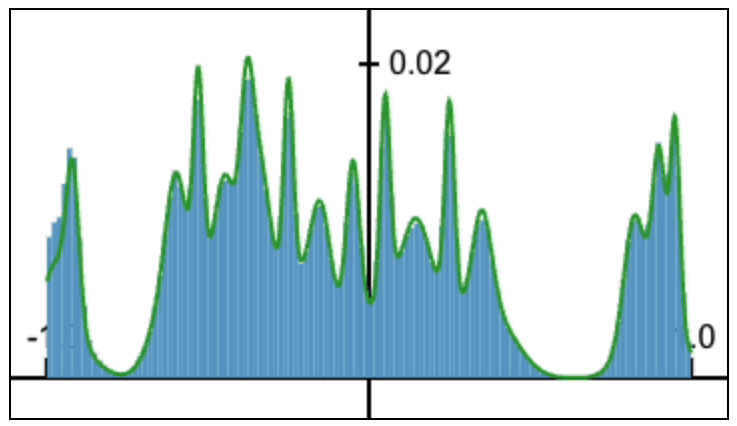
Fourier Head: Helping Large Language Models Learn Complex Probability Distributions
Nate Gillman*, Daksh Aggarwal*, Michael Freeman, Saurabh Singh, and Chen Sun
ICLR 2025
arXiv / Project / Code
|
|
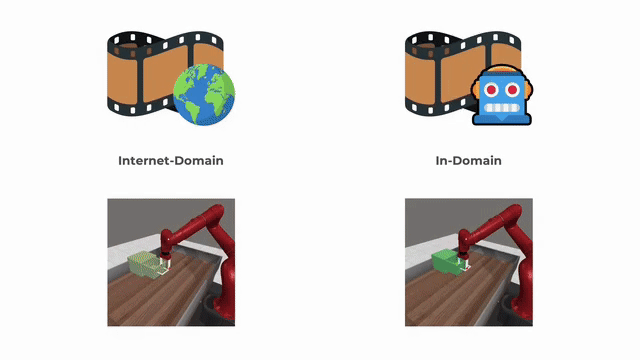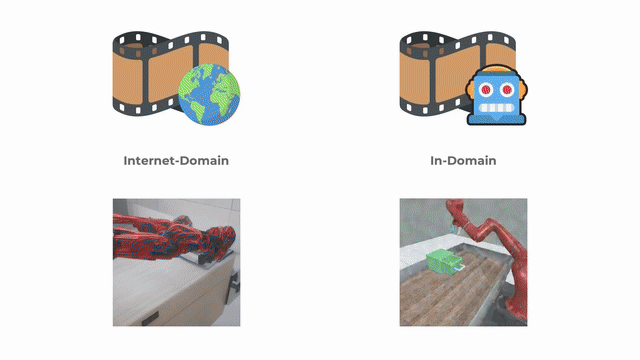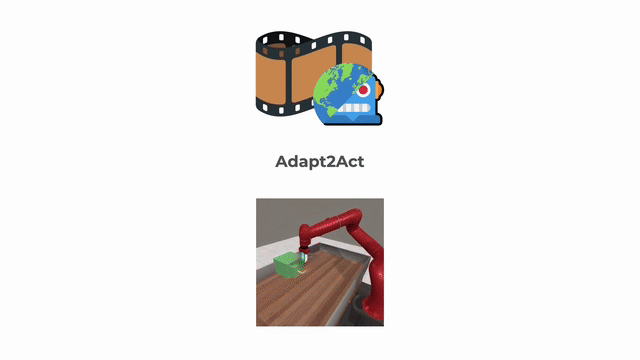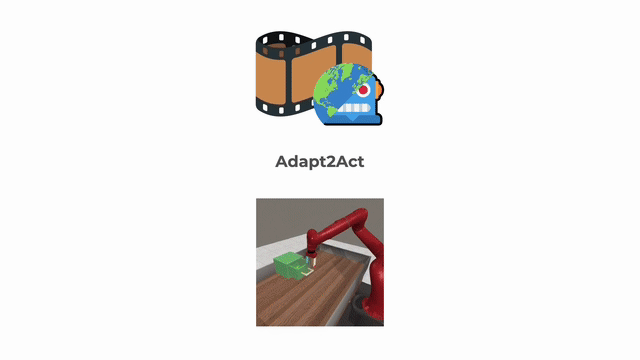
Solving New Tasks by Adapting Internet Video Knowledge
Calvin Luo*, Zilai Zeng*, Yilun Du, and Chen Sun
ICLR 2025
arXiv / Project / Code
|

|
Motion Prompting: Controlling Video Generation with Motion Trajectories
Daniel Geng, Charles Herrmann et al.
CVPR 2025 (Oral)
arXiv / Project
|
|
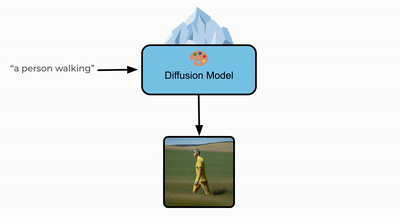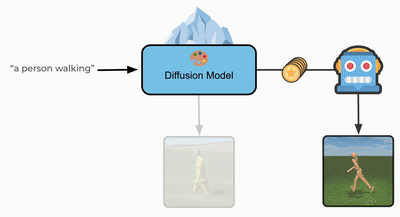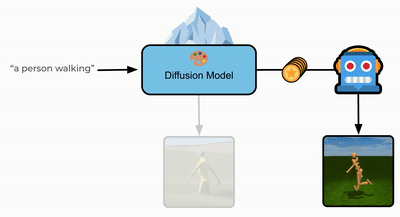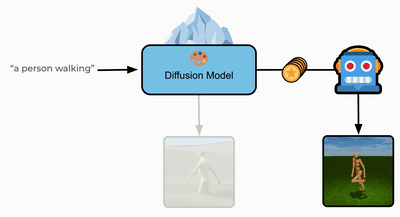
Text-Aware Diffusion for Policy Learning
Calvin Luo, Mandy He*, Zilai Zeng*, and Chen Sun
NeurIPS 2024
(Also appeared at NeurIPS 2023 workshop on Diffusion Models)
arXiv / Poster / Project / Code
|
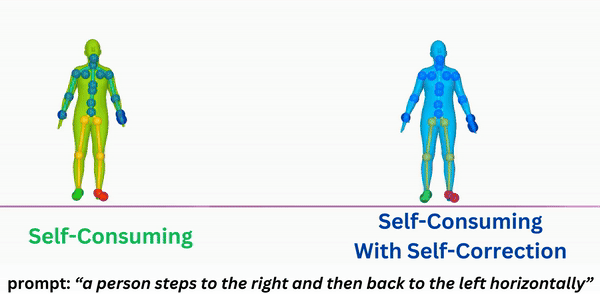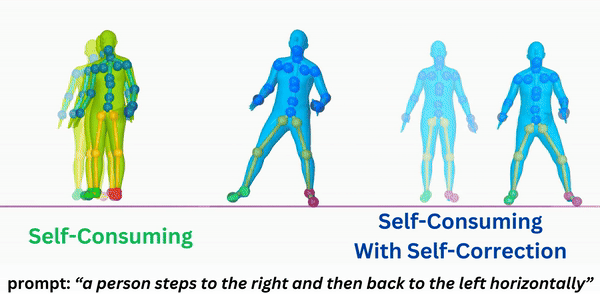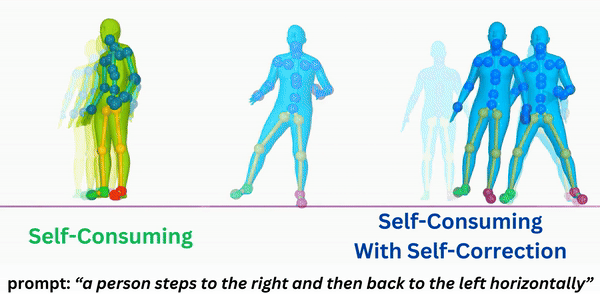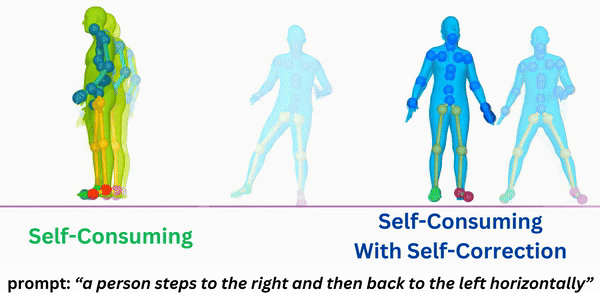
|
Self-Correcting Self-Consuming Loops for Generative Model Training
Nate Gillman, Michael Freeman, Daksh Aggarwal, Chia-Hong Hsu, Calvin Luo, Yonglong Tian, and Chen Sun
ICML 2024
arXiv / Poster / Project / Code
|

|
Vamos: Versatile Action Models for Video Understanding
Shijie Wang, Qi Zhao, Minh Quan Do, Nakul Agarwal, Kwonjoon Lee, and Chen Sun
ECCV 2024
arXiv / Project / Code
|
|
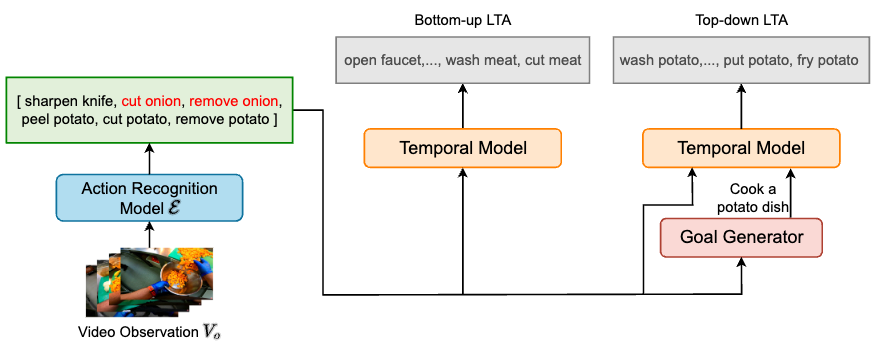
AntGPT: Can Large Language Models Help Long-term Action Anticipation from Videos?
Qi Zhao*, Shijie Wang*, Ce Zhang, Changcheng Fu, Minh Quan Do, Nakul Agarwal, Kwonjoon Lee, and Chen Sun
ICLR 2024
arXiv / Project / Code
|
|
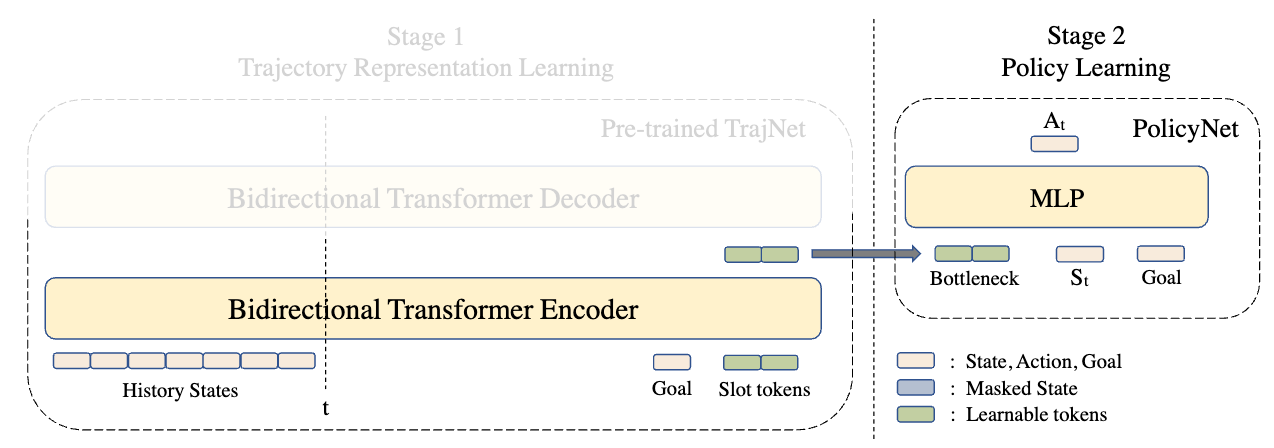
Goal-Conditioned Predictive Coding for Offline Reinforcement Learning
Zilai Zeng, Ce Zhang, Shijie Wang, and Chen Sun
NeurIPS 2023
arXiv / Project / Code
|
|
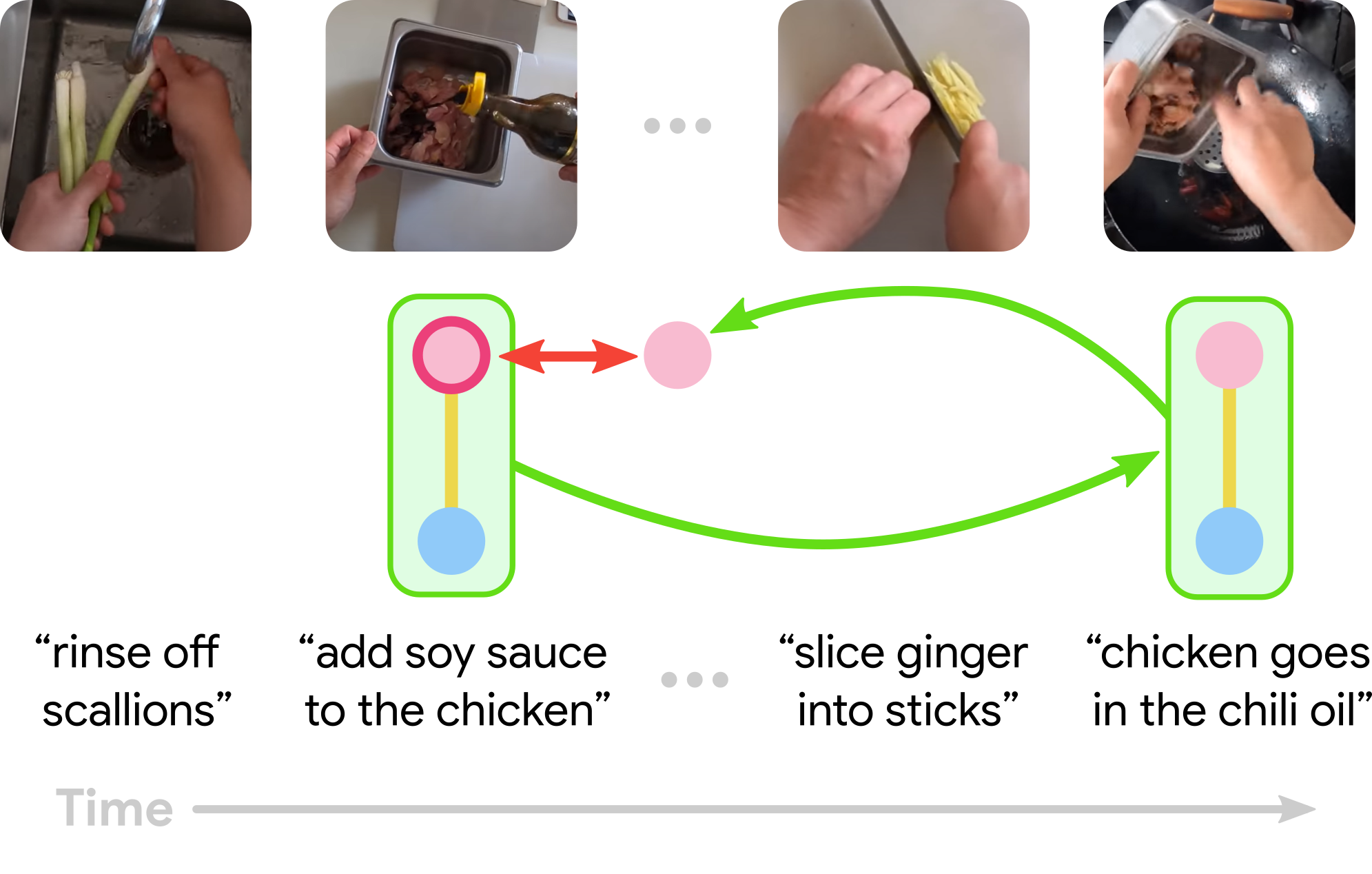
Learning Temporal Dynamics from Cycles in Narrated Video
Dave Epstein, Jiajun Wu, Cordelia Schmid, and Chen Sun
ICCV 2021
arXiv / Research Blog / Project
|
|
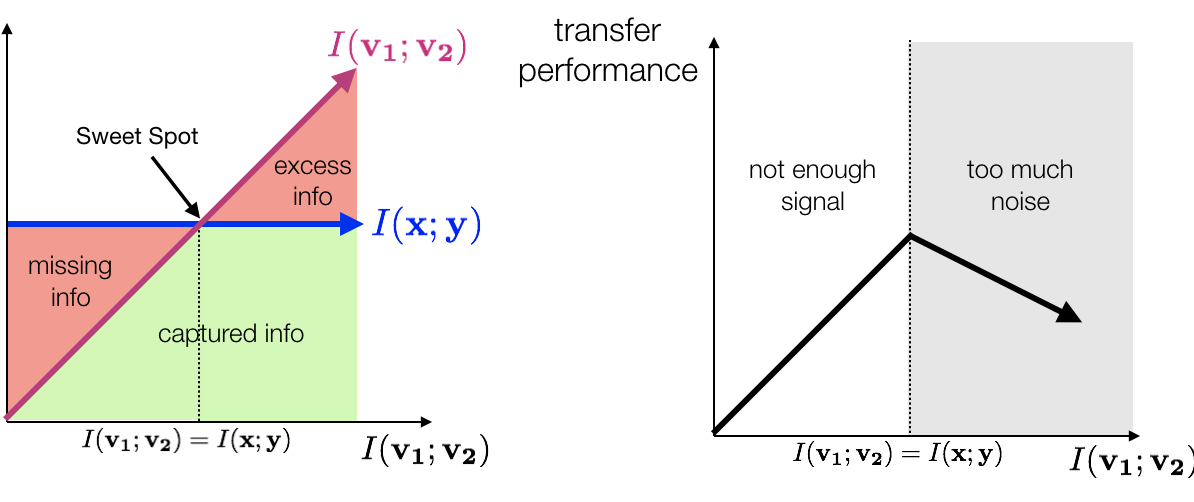
What Makes for Good Views for Contrastive Learning?
Yonglong Tian, Chen Sun, Ben Poole, Dilip Krishnan, Cordelia Schmid, and Phillip Isola
NeurIPS 2020
arXiv / Research Blog / Project / Code
|

|
VectorNet: Encoding HD Maps and Agent Dynamics from Vectorized Representation
Jiyang Gao*, Chen Sun*, Hang Zhao, Yi Shen, Dragomir Anguelov, Congcong Li, and Cordelia Schmid
CVPR 2020
arXiv / Waymo Blog / VentureBeat
|
|
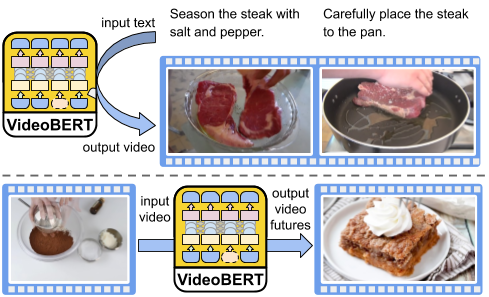
VideoBERT: A Joint Model for Video and Language Representation Learning
Chen Sun, Austin Myers, Carl Vondrick, Kevin Murphy, and Cordelia Schmid
ICCV 2019
arXiv / Research Blog / VentureBeat
|
